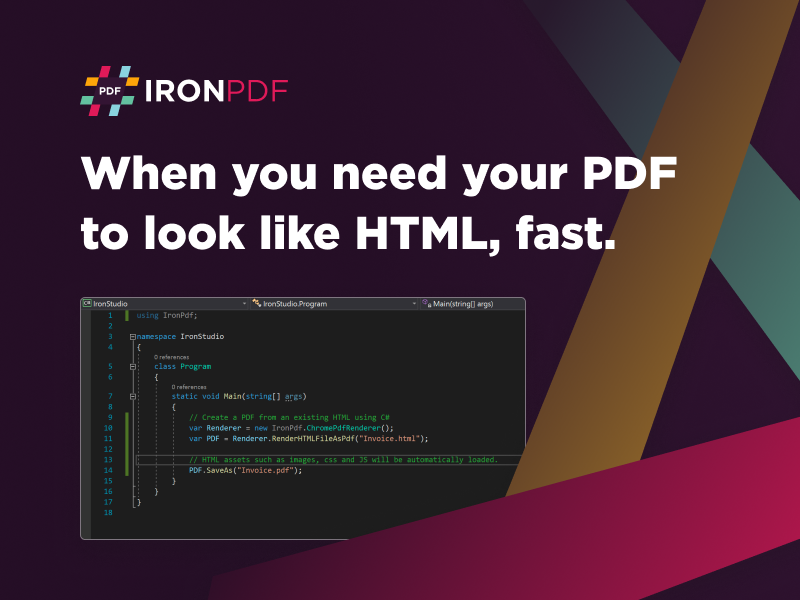
Extract Text From PDF Python Tutorial
4.63/5 (177 Reviews)
Extracting text from PDF documents is a common task in various fields, including data analysis, natural language processing, and information retrieval.
Development And IT
Languages And Scripts
Shareware
FREE DOWNLOAD (v2023.8.6)
File Size: 232335KB | Official Download
Key Features of Extract Text From PDF Python
- Extracting text from PDF documents is a common task in various fields, including data analysis, natural language processing, and information retrieval.
- Python, being a versatile programming language, provides a powerful PDF library that simplifies the process of extracting text from PDF files.
- With the help of this Python PDF library, developers can effortlessly retrieve textual content from PDFs and unlock valuable insights from the data within.
Technical Specifications
- Publisher: Ironpdf.com
- License: Shareware
- Operating System: Windows 7, Windows 8, Windows 10, Windows 11
- Category: Development And IT / Languages And Scripts
Extract Text From PDF Python Screenshot